绘制 UMAP 结果
UMAP 经常用于通过将数据降维到 2 维来进行可视化。由于这是一个非常常见的用例,umap 软件包现在包含了实用程序例程,可以简化 UMAP 结果的绘制,并提供多种查看和诊断结果的方法。此 umap 扩展不是旨在提供一个涵盖所有可能绘图需求的全面解决方案,而是旨在提供一个易于使用的接口,使大多数绘图需求变得简单,并尽可能提供合理的绘图选项。要开始了解绘图选项,让我们加载各种数据进行处理。
import sklearn.datasets
import pandas as pd
import numpy as np
import umap
pendigits = sklearn.datasets.load_digits()
mnist = sklearn.datasets.fetch_openml('mnist_784')
fmnist = sklearn.datasets.fetch_openml('Fashion-MNIST')
首先,我们将使用 pendigits 数据拟合一个 UMAP 模型。这就像运行 fit 方法并将结果赋给一个变量一样简单。
mapper = umap.UMAP().fit(pendigits.data)
如果我们要进行绘图,就需要 umap.plot 包。虽然 umap 包的要求相对较少,但值得注意的是,如果您想使用 umap.plot,您将需要许多额外的库,这些库不包含在 umap 的默认要求中。特别是您将需要
所有这些库都可以通过 pip 或 conda 安装。安装完成后,您可以导入 umap.plot 包。
import umap.plot
现在我们已经加载了软件包,如何使用它呢?最直接的方法是将 umap 结果绘制成散点图。我们可以通过函数 umap.plot.points 来实现。在其最基本的形式中,您只需将训练好的 UMAP 模型传递给 umap.plot.points
umap.plot.points(mapper)

正如您所见,我们立即得到了 UMAP 嵌入的散点图。请注意,该函数会根据数据密度自动选择点的大小,并用水印标记所使用的 UMAP 参数(如果使用非标准度量,也会包含度量信息)。该函数还会返回与绘图关联的 matplotlib axes 对象,因此如果需要,用户可以应用进一步的 matplotlib 函数,例如添加标题、轴标签等。
传递给 UMAP 的数据通常会有一组相关的标签,这些标签可能来自真实标签、聚类或其他方法。在这种情况下,根据标签信息为散点图着色是很理想的。我们可以通过使用 labels 关键字传递标签信息数组来实现这一点。umap.plot.points 函数将根据提供的标签使用分类颜色映射为数据着色。
umap.plot.points(mapper, labels=pendigits.target)

或者,您可能有连续而非分类的额外数据。在这种情况下,您会希望使用连续颜色映射来为数据着色。同样,这也很容易做到——使用 values 关键字传入连续数据,数据将相应地使用连续颜色映射进行着色。
此外,如果您不喜欢默认的颜色选择,umap.plot.points 函数提供了许多“主题”,这些主题提供了预定义的颜色选择。主题包括
fire
viridis
inferno
blue
red
green
darkblue
darkred
darkgreen
这里我们将使用 ‘fire’ 主题来演示更改美观性有多简单。
umap.plot.points(mapper, values=pendigits.data.mean(axis=1), theme='fire')
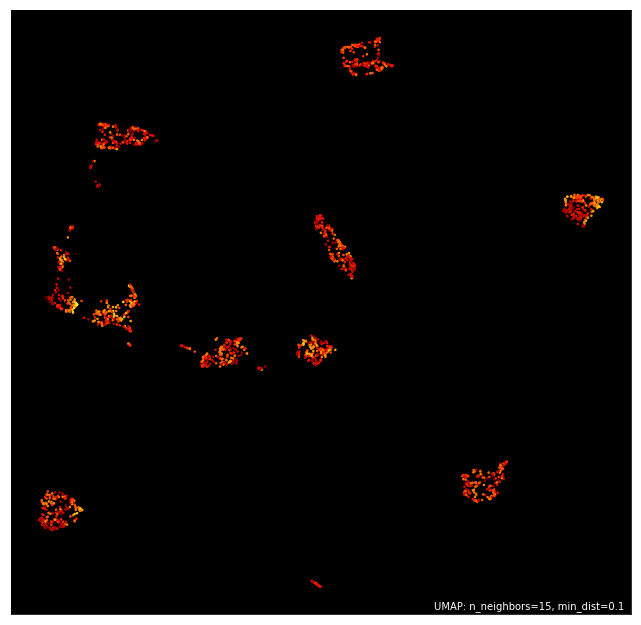
如果您想要更大的控制权,可以指定精确的颜色映射和背景颜色。例如,这里我们想按标签为数据着色,但使用黑色背景,并使用 ‘Paired’ 颜色映射进行分类着色(通过 color_key_cmap 传递;cmap 关键字定义连续颜色映射)。
umap.plot.points(mapper, labels=pendigits.target, color_key_cmap='Paired', background='black')

还提供了更多选项,包括使用 color_key 指定离散标签到颜色的字典映射,使用 cmap 指定连续颜色映射,或指定生成图的宽度和高度。同样,这并未提供对绘图美观性的全面控制,但这里的目标是提供一个易于使用的接口,而不是让用户能够微调所有方面——寻求此类控制的用户最好自己使用底层的各个软件包(matplotlib、datashader 和 bokeh)。
绘制大型数据集
一旦数据量很大,简单的散点图就很容易误导您。最值得注意的是,点标记相互重叠和堆积的过度绘制(overplotting)会让您误以为极密集的数据块只包含少数点。虽然有一些方法可以弥补这一点,例如减小点的大小或添加 alpha 通道,但很少有方法足以确保绘图不会在某种程度上巧妙地欺骗您。datashader 文档中的 这篇论文 很好地描述了过度绘制的问题,为什么显而易见的解决方案不够充分,以及如何解决这个问题。为了让用户更容易,当您的数据集足够大时,umap.plot 包会自动切换到使用 datashader 进行渲染。这有助于确保您不会被过度绘制所误导。
mapper = umap.UMAP().fit(fmnist.data)
使用 UMAP 拟合数据后,我们可以像之前一样调用 umap.plot.points,但这次,由于数据足够大可能存在过度绘制,datashader 将在后台用于渲染。
umap.plot.points(mapper)

所有与之前相同的绘图选项仍然有效,因此我们可以按标签着色,并应用相同的主题,所有这些都将无缝地使用 datashader 进行实际渲染。因此,无论您拥有多少数据,umap.plot.points 都会通过透明的用户界面很好地进行渲染。作为用户,您无需担心切换到使用 datashader 绘图,或如何将您的绘图转换为其略有不同的 API – 您只需使用相同的 API 并相信您获得的结果即可。
umap.plot.points(mapper, labels=fmnist.target, theme='fire')

交互式绘图和悬停工具
渲染美观的静态图很重要,但如果您想与数据交互——平移和放大集群以查看更精细的结构呢?如果您想使用比颜色更复杂的标签来标注数据呢?如果能够将鼠标悬停在数据点上并获取有关单个点的更多信息,那不是很好吗?由于这是一个非常常见的用例,umap.plot 试图使其易于快速生成此类图,并提供基本实用程序,让您能够快速使用带注释的悬停工具。同样,目标不是提供一个无所不能的全面解决方案,而是提供一个易于使用且一致的 API,让用户能够快速上手。
为了更好地演示这一点,让我们使用 Fashion MNIST 数据集的一个子集。我们可以快速地在该子集上训练一个新的映射器对象。
mapper = umap.UMAP().fit(fmnist.data[:30000])
目标是能够将鼠标悬停在不同的点上,并查看与光标下的给定点(或多个点)相关联的数据。对于这个简单的演示,我们将仅使用点的目标信息。要创建悬停信息,您需要构建一个包含所有您希望显示在悬停中的数据的 DataFrame。每一行应对应一个数据点源(按相同顺序出现),列可以提供您希望在悬停工具提示中显示的任何额外数据。在本例中,我们将需要一个可以包含点索引、其目标编号以及该目标对应的时尚物品类型的实际名称的 DataFrame。使用 pandas 可以轻松快速地完成此操作。
hover_data = pd.DataFrame({'index':np.arange(30000),
'label':fmnist.target[:30000]})
hover_data['item'] = hover_data.label.map(
{
'0':'T-shirt/top',
'1':'Trouser',
'2':'Pullover',
'3':'Dress',
'4':'Coat',
'5':'Sandal',
'6':'Shirt',
'7':'Sneaker',
'8':'Bag',
'9':'Ankle Boot',
}
)
对于交互式使用,umap.plot 包使用了 bokeh。Bokeh 有几种输出方法,但在本方法中,我们将在 notebook 中以内联方式输出。我们必须使用 output_notebook 函数启用此功能。或者,我们可以使用 output_file 或其他类似选项——更多详情请参阅 bokeh 文档。
umap.plot.output_notebook()
现在我们可以使用 umap.plot.interactive 创建交互式绘图。它的 API 与 umap.plot.points 方法非常相似,但也支持 hover_data 关键字,如果传入合适的 DataFrame,它将在交互式图中提供悬停工具提示。由于 bokeh 允许不同的输出方式,要在 notebook 中显示它,我们需要额外调用 show 函数来显示结果。
p = umap.plot.interactive(mapper, labels=fmnist.target[:30000], hover_data=hover_data, point_size=2)
umap.plot.show(p)
我们得到了我们想要的结果——一个可以缩放等功能的完全交互式绘图,同时我们现在还有一个交互式悬停工具,可以显示我们构建的 DataFrame 中的数据。这提供了一种快速简便的方法,让您可以更丰富地交互式探索 UMAP 绘图。umap.plot.interactive 支持与 umap.plot.points 相同的所有美观参数,因此您可以为主图设置主题,按标签或值着色,以及执行上面为 umap.plot.points 解释的其他类似操作。
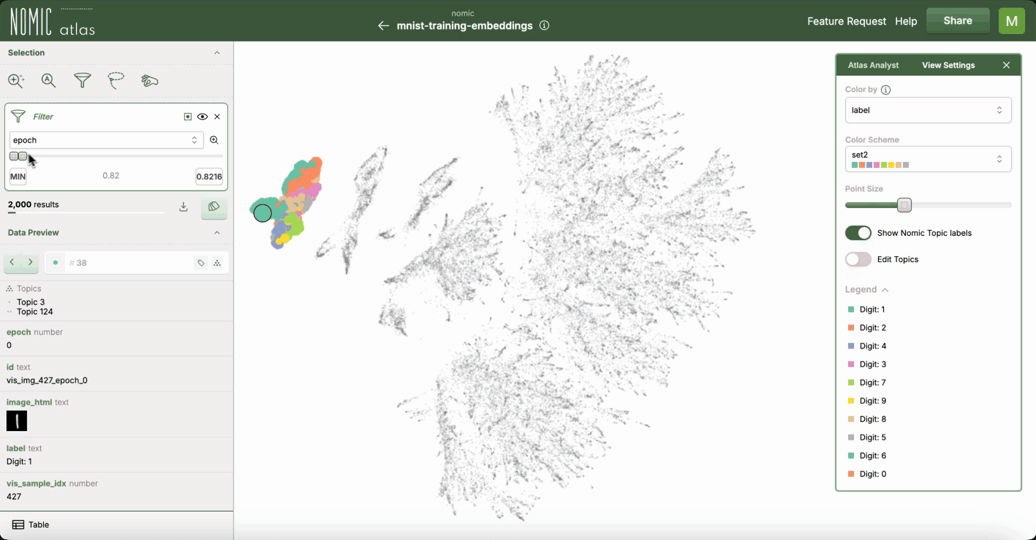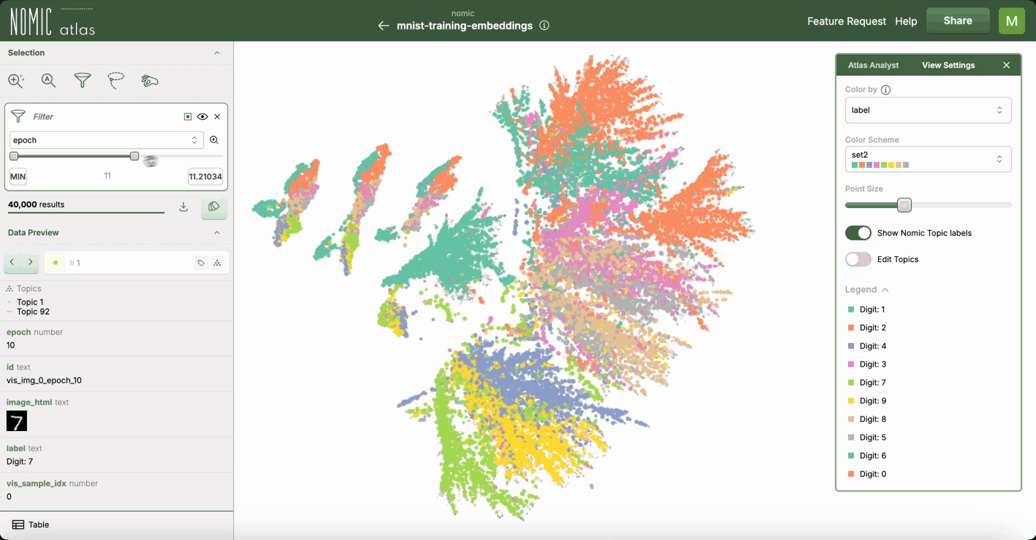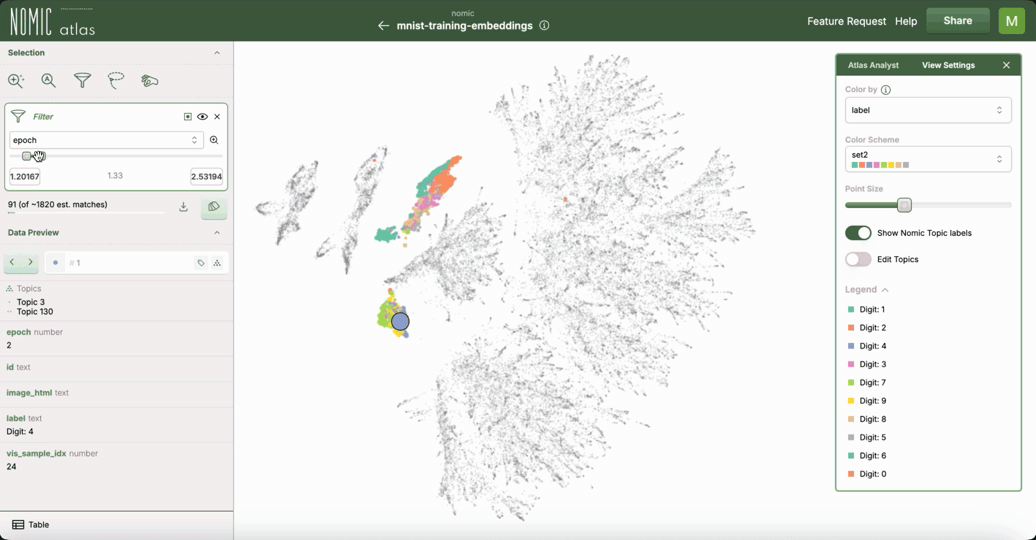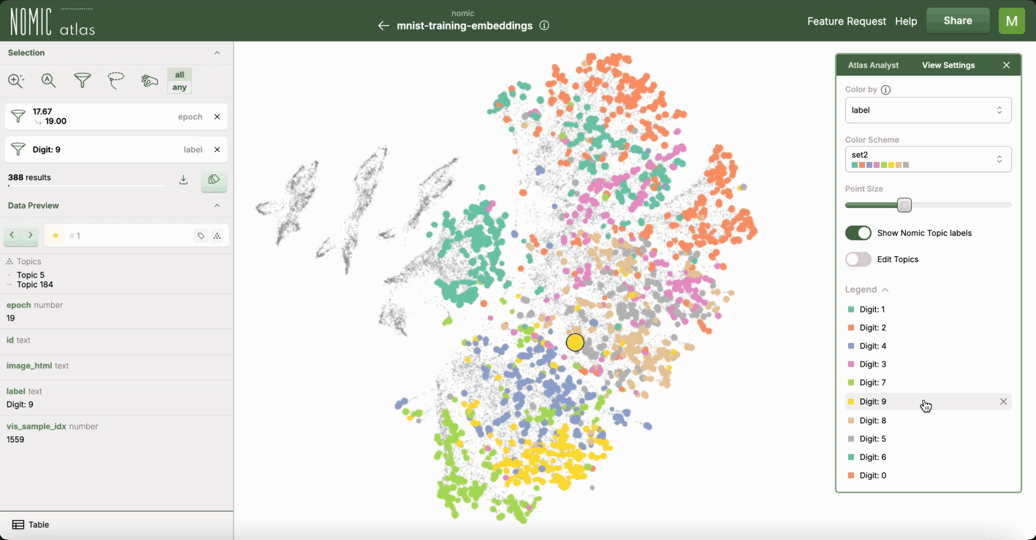
使用 Nomic Atlas 进行交互式绘图
对于交互式探索,特别是大型数据集,您可以使用 Nomic Atlas。Nomic Atlas 是一个用于嵌入生成、可视化、分析、检索以及将您的嵌入投入实际应用所需的一切的平台。它将 UMAP 直接集成作为其投影模型之一,使您能够在强大的可视化环境中利用 UMAP。
Nomic Atlas 处理嵌入和 UMAP 降维过程,并提供具有搜索、过滤、按元数据着色以及在悬停时显示丰富信息等功能的交互式界面。当您想分享对 UMAP 可视化的理解或与他人协作时,Atlas 会有所帮助,因为可以通过 URL 访问地图。
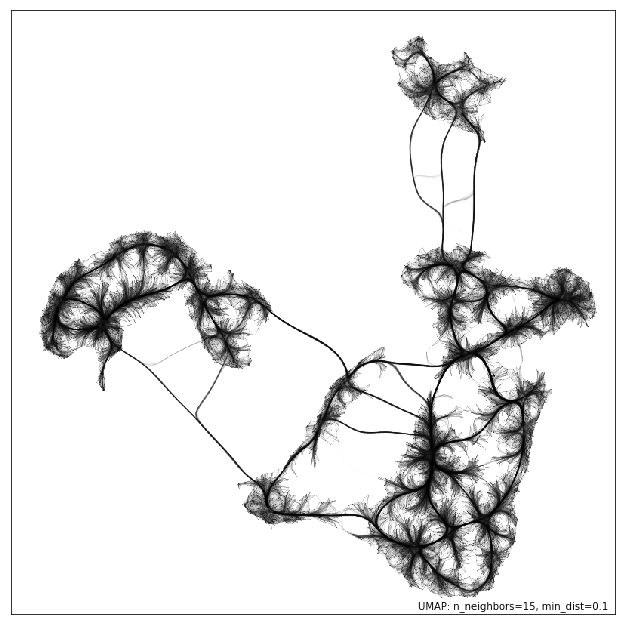
绘制连通性
UMAP 通过构建数据可能从中采样的近似流形的中间拓扑表示来工作。实际上,这种结构可以简化为一个加权图。有时,查看该图(代表流形中的连通性)相对于结果嵌入的形状会很有益。它可以用于更好地理解嵌入,以及用于诊断目的。要查看连通性,可以使用 umap.plot.connectivity 函数。它的工作方式与 umap.plot.points 函数非常相似,并且可以选择是显示嵌入点,还是仅显示连通性。首先,我们做一个显示点的简单图
umap.plot.connectivity(mapper, show_points=True)

与 umap.plot.points 一样,也有控制基本美观性的选项,包括主题选项和用于指定边缘显示颜色映射的 edge_cmap 关键字参数。
由于此方法已经利用 datashader 进行边缘绘制,我们可以进一步利用 datashader 中可用的边缘捆绑选项。这可以提供一个不那么杂乱的连通性视图,但计算成本可能较高,特别是对于大型数据集。
umap.plot.connectivity(mapper, edge_bundling='hammer')
诊断绘图
绘制连通性至少提供了一个基本的诊断视图,帮助用户了解嵌入的情况。当然,更多的数据视图更好,因此 umap.plot 包含一个 umap.plot.diagnostic 函数,可以提供各种诊断图。我们将在这里查看其中几个。为此,我们将使用完整的 MNIST 数字数据集。
mapper = umap.UMAP().fit(mnist.data)
第一种诊断类型是基于主成分分析(PCA)的诊断,您可以使用 diagnostic_type='pca' 进行选择。该方法的本质是我们可以使用保留全局结构的 PCA 将数据降维到三维。如果我们将结果缩放到适合 3D 立方体,我们可以将每个点的 3D PCA 坐标转换为颜色的 RGB 描述。然后通过使用 PCA 诱导的颜色为 UMAP 嵌入中的点着色,可以了解一些更大型的全局结构在嵌入中是如何表示的。
umap.plot.diagnostic(mapper, diagnostic_type='pca')

我们在这里寻找的是颜色的整体平滑过渡,以及大致遵循颜色过渡的整体布局。在这种情况下,最左侧有一个底部集群,颜色从底部深绿色过渡到顶部蓝色,这与右上角的集群很好地匹配,右上角集群底部有类似的蓝色阴影,然后过渡到更多青色和蓝色。相比之下,在绘图的右侧,下方的集群颜色从上到下从紫粉色变为绿色,而其上方的集群的底部边缘更偏紫色而非绿色,这表明在优化过程中,这些集群中的一个或另一个可能垂直翻转了,并且从未完全纠正。
另一种但类似的方法是使用向量量化作为生成 3D 嵌入以生成颜色的方法。向量量化有效地找到数据的 3 个代表性中心,然后根据数据点与这些中心的距离来描述每个数据点。显然,这再次捕捉了数据的许多广泛全局结构。
umap.plot.diagnostic(mapper, diagnostic_type='vq')

同样,我们寻找的是大致平滑的过渡,以及相关颜色在集群之间匹配。此视图支持嵌入的左侧运行良好,但查看右侧,似乎很明显是上方两个集群无意中垂直翻转了。通过对比这样的视图,可以更好地了解嵌入的效果如何。
换个角度,我们可以看看每个数据点周围局部维度的近似值。理想情况下,局部维度应该与嵌入维度匹配(尽管这通常是奢望)。实际上,当局部维度很高时,这代表 UMAP 也会更难嵌入的点(或空间区域)。因此,在点具有一致较低局部维度的区域,可以更信任嵌入的准确性。
local_dims = umap.plot.diagnostic(mapper, diagnostic_type='local_dim')
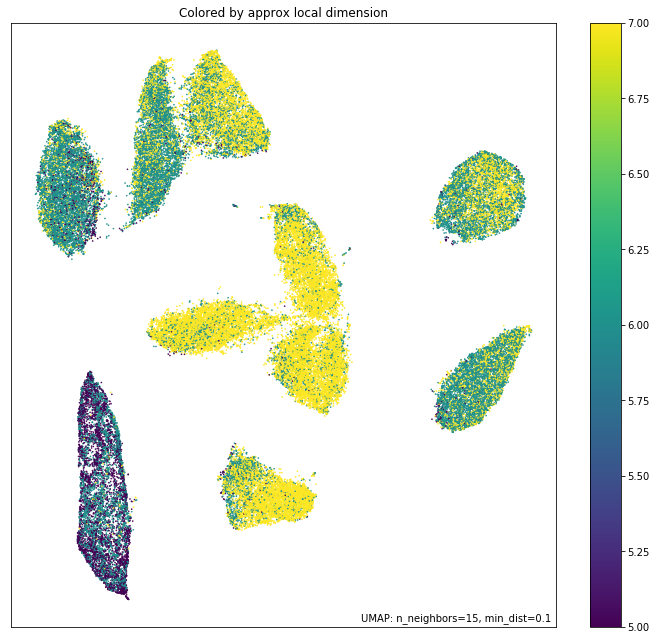
正如您所见,数据的局部维度在整个数据中变化相当大。特别是左下角的集群局部维度最低——这实际上并不令人惊讶,因为这是对应于数字 1 的集群:一个人画数字 1 的方式只有相对较少的自由度,因此产生的局部维度较低。相比之下,中间的集群具有更高的局部维度。我们应该预料到在这些区域嵌入的准确性会稍差:在只有两个维度的情况下很难很好地表示七维数据,需要做出妥协。
我们将查看的最后一个诊断是局部邻域保留得有多好。我们可以通过高维空间中局部邻域与嵌入中等效邻域的 Jaccard 指数来衡量这一点。Jaccard 指数本质上是两个邻域共同的邻居数量与这两个邻域中所有唯一邻居总数之比。值越高意味着局部邻域保留得越准确。
umap.plot.diagnostic(mapper, diagnostic_type='neighborhood')
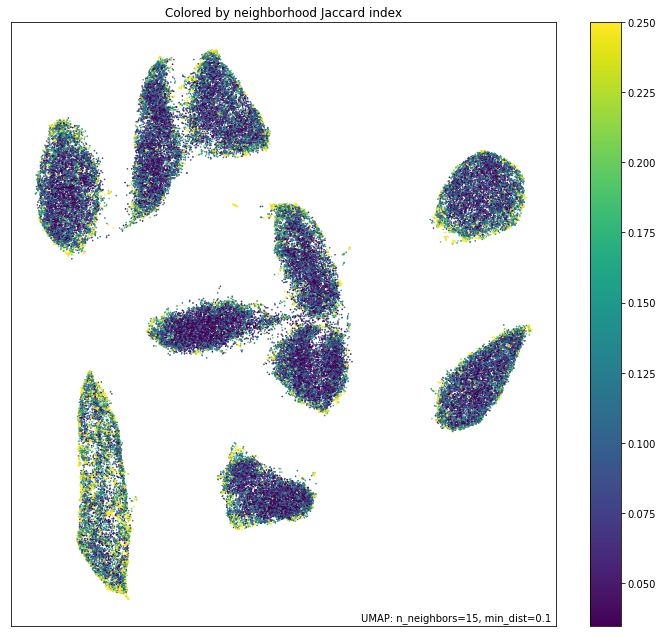
正如所料,局部邻域保留对于局部维度较低的点(如上图所示)往往要好得多。集群边缘(有清晰边界可循的地方)也比局部维度较高的集群中心更好地保留了邻域。同样,这提供了关于嵌入的哪些区域您可以更信任,以及哪些区域为了嵌入到二维空间而不得不做出妥协的视角。