参数化(神经网络)嵌入
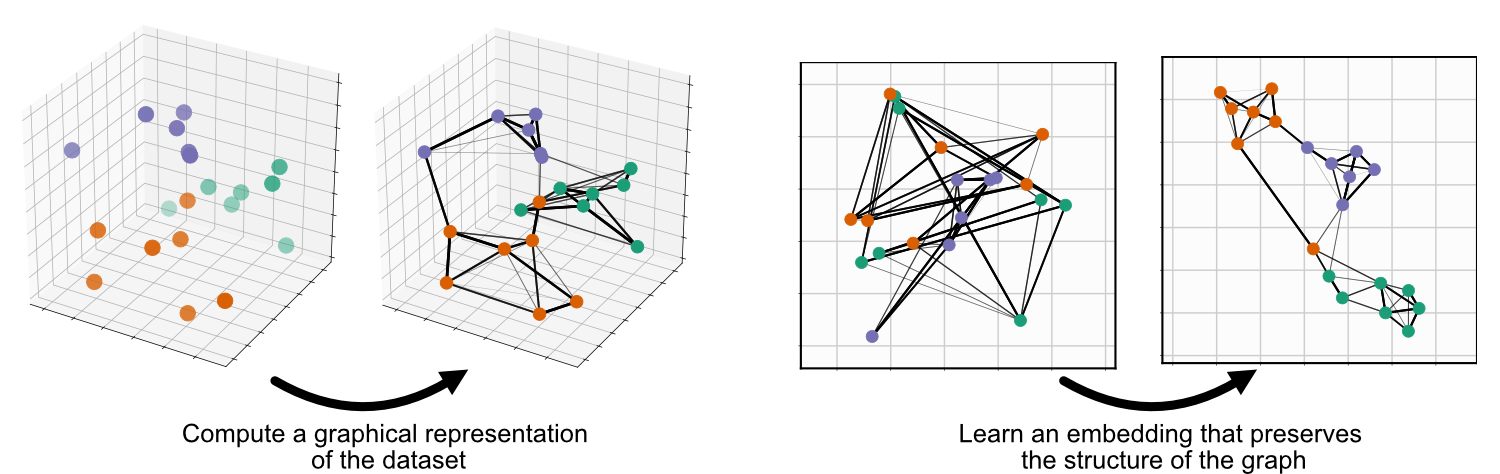
UMAP 包含两个步骤:首先,计算代表您数据的图;其次,学习该图的嵌入
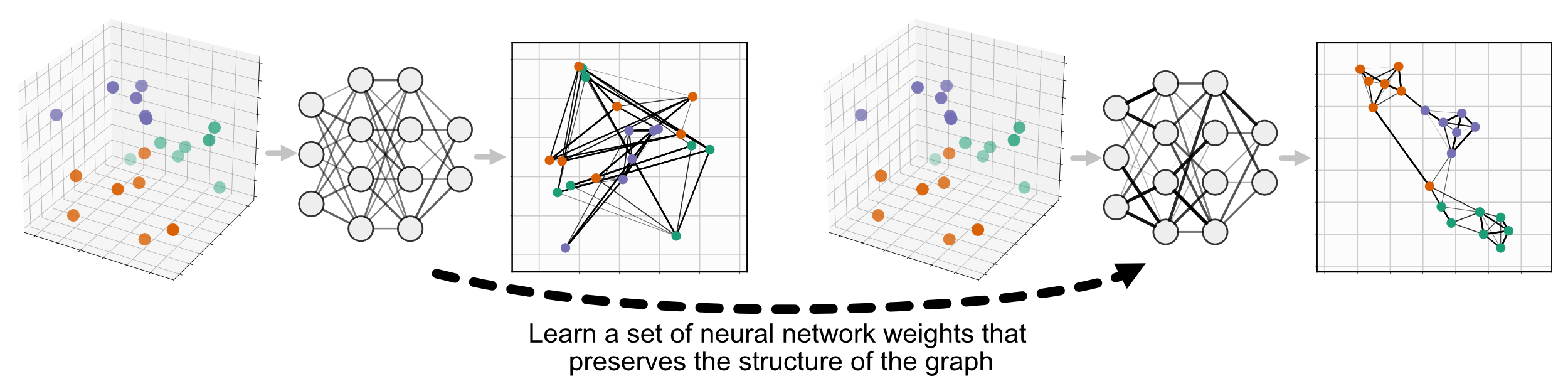
参数化 UMAP 取代了第二个步骤,最小化与 UMAP(在此我们称之为非参数化 UMAP)相同的目标函数,但使用神经网络学习数据和嵌入之间的关系,而不是直接学习嵌入本身
参数化 UMAP 只是 UMAP 的一个子类,因此可以像非参数化 UMAP 一样使用,只需将 umap.UMAP 替换为 parametric_umap.ParametricUMAP。参数化 UMAP 的最基本用法就是简单地在代码中将 UMAP 替换为 ParametricUMAP
from umap.parametric_umap import ParametricUMAP
embedder = ParametricUMAP()
embedding = embedder.fit_transform(my_data)
在此实现中,我们使用 Keras 和 Tensorflow 作为后端来训练该神经网络。学习嵌入的额外复杂性带来了许多额外的可配置设置,这些设置在非参数化 UMAP 中没有。在 GitHub 仓库上有一系列 Jupyter Notebook,可以指导您了解这些参数
定义自己的网络
默认情况下,参数化 UMAP 使用 3 层 100 个神经元的全连接神经网络。要扩展参数化 UMAP 以使用更复杂的架构,例如卷积神经网络,我们只需要定义网络并将其作为参数传递给 ParametricUMAP。使用 tf.keras.Sequential 可以轻松完成此操作。以下是 MNIST 的示例
# define the network
import tensorflow as tf
dims = (28, 28, 1)
n_components = 2
encoder = tf.keras.Sequential([
tf.keras.layers.InputLayer(input_shape=dims),
tf.keras.layers.Conv2D(
filters=32, kernel_size=3, strides=(2, 2), activation="relu", padding="same"
),
tf.keras.layers.Conv2D(
filters=64, kernel_size=3, strides=(2, 2), activation="relu", padding="same"
),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(units=256, activation="relu"),
tf.keras.layers.Dense(units=256, activation="relu"),
tf.keras.layers.Dense(units=n_components),
])
encoder.summary()
要将数据加载到 ParametricUMAP 中,我们首先需要将其从 28x28x1 的图像展平为 784 维向量。
from tensorflow.keras.datasets import mnist
(train_images, Y_train), (test_images, Y_test) = mnist.load_data()
train_images = train_images.reshape((train_images.shape[0], -1))/255.
test_images = test_images.reshape((test_images.shape[0], -1))/255.
然后我们可以将网络传递给 ParametricUMAP 并进行训练
# pass encoder network to ParametricUMAP
embedder = ParametricUMAP(encoder=encoder, dims=dims)
embedding = embedder.fit_transform(train_images)
如果您不熟悉 Tensorflow/Keras 并想训练自己的模型,我们建议您查看 Tensorflow 文档。
保存和加载模型
与非参数化 UMAP 不同,参数化 UMAP 不能仅仅通过 pickle UMAP 对象来保存,因为它包含 Keras 网络。为了保存参数化 UMAP,有一个内置函数
embedder.save('/your/path/here')
然后您可以在其他地方加载参数化 UMAP
from umap.parametric_umap import load_ParametricUMAP
embedder = load_ParametricUMAP('/your/path/here')
这将加载 UMAP 对象及其包含的参数化网络。
绘制损失曲线
参数化 UMAP 在训练期间使用 Keras 监控损失。每次训练 epoch 后会打印该损失。此损失保存在 embedder._history 中,并可以进行绘制
print(embedder._history)
fig, ax = plt.subplots()
ax.plot(embedder._history['loss'])
ax.set_ylabel('Cross Entropy')
ax.set_xlabel('Epoch')
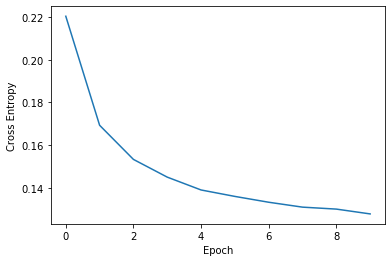
与其他 Keras 模型类似,如果您通过模型的 fit 方法继续训练模型,embedder._history 将随着进一步的训练 epoch 损失进行更新。
参数化逆变换(重构)
要使用第二个神经网络学习数据和嵌入之间的逆映射,我们只需将 parametric_reconstruction= True 传递给 ParametricUMAP。
与编码器类似,也可以将自定义解码器传递给 ParametricUMAP,例如
decoder = tf.keras.Sequential([
tf.keras.layers.InputLayer(input_shape=(n_components)),
tf.keras.layers.Dense(units=256, activation="relu"),
tf.keras.layers.Dense(units=7 * 7 * 256, activation="relu"),
tf.keras.layers.Reshape(target_shape=(7, 7, 256)),
tf.keras.layers.UpSampling2D((2)),
tf.keras.layers.Conv2D(
filters=64, kernel_size=3, padding="same", activation="relu"
),
tf.keras.layers.UpSampling2D((2)),
tf.keras.layers.Conv2D(
filters=32, kernel_size=3, padding="same", activation="relu"
),
])
此外,可以使用验证数据来测试数据集外样本的重构损失
validation_images = test_images.reshape((test_images.shape[0], -1))/255.
最后,我们可以将验证数据和网络传递给 ParametricUMAP 并进行训练
embedder = ParametricUMAP(
encoder=encoder,
decoder=decoder,
dims=dims,
parametric_reconstruction= True,
reconstruction_validation=validation_images,
verbose=True,
)
embedding = embedder.fit_transform(train_images)
自编码 UMAP
在上面的示例中,编码器被训练来最小化 UMAP 损失,解码器被训练来最小化重构损失。要同时在 UMAP 损失和重构损失上联合训练编码器,请将 autoencoder_loss = True 传递到 ParametricUMAP 中。
embedder = ParametricUMAP(
encoder=encoder,
decoder=decoder,
dims=dims,
parametric_reconstruction= True,
reconstruction_validation=validation_images,
autoencoder_loss = True,
verbose=True,
)
提前停止和 Keras 回调
有时,将嵌入器训练到训练损失达到某个平台期会很有用。在深度学习中,提前停止是一种实现方法。Keras 提供了自定义的 回调,允许您在训练期间实现检查,例如提前停止。我们可以使用回调(例如提前停止)与 ParametricUMAP 一起,根据预定义的训练阈值提前停止训练,使用 keras_fit_kwargs 参数
keras_fit_kwargs = {"callbacks": [
tf.keras.callbacks.EarlyStopping(
monitor='loss',
min_delta=10**-2,
patience=10,
verbose=1,
)
]}
embedder = ParametricUMAP(
verbose=True,
keras_fit_kwargs = keras_fit_kwargs,
n_training_epochs=20
)
我们还传入了 n_training_epochs = 20,允许提前停止在达到 20 个 epoch 之前结束训练。
更多重要参数
batch_size:参数化 UMAP 通过从 UMAP 图中随机采样的边批量进行训练,然后通过梯度下降进行训练。参数化 UMAP 默认的批量大小为 1000 条边,但可以调整为更适合您的 GPU 或 CPU 的值。
loss_report_frequency:如果设置为 1,则 Keras 嵌入中的一个 epoch 指的是在 UMAP 中计算的图上的一次迭代。将
loss_report_frequency设置为 10,会将该 epoch 分割成 10 个独立的 epoch,以便更频繁地报告。n_training_epochs:在 UMAP 图上训练的 epoch 数(与
loss_report_frequency无关)。训练网络多个 epoch 将产生更好的嵌入,但耗时更长。此参数与基础 UMAP 类中的n_epochs不同,后者对应于单个参数化 UMAP epoch 中训练边的最大次数。optimizer:用于训练神经网络的优化器。默认使用 Adam (
tf.keras.optimizers.Adam(1e-3))。您可能通过使用不同的优化器来加速或改进训练。parametric_embedding:如果设置为 false,将学习非参数化嵌入,使用与参数化嵌入相同的代码,这可以作为使用相同优化器对参数化和非参数化嵌入进行直接比较。参数化嵌入是同时在整个数据集上执行的。
global_correlation_loss_weight:是否额外在全局成对关系的相关性上进行训练(多维尺度分析)
landmark_loss_fn:在对有标志的数据进行再训练时使用的损失函数,您已将嵌入空间中的期望位置提供给模型的
fit方法。默认使用欧几里得损失。有关再训练、标志以及为何使用它们的更多信息,请参见 使用参数化 UMAP 转换新数据。landmark_loss_weight:相对于 umap 损失,如何加权标志损失,默认为 1.0。
扩展模型
您可能希望在本文档实现的功能之外定制参数化 UMAP。为了尽可能方便您对参数化 UMAP 进行修改,我们制作了一些 Jupyter Notebook,展示了如何将参数化 UMAP 扩展到您自己的用例。
引用我们的工作
如果您在工作中使用参数化 UMAP,请引用我们的论文
@article{sainburg2021parametric,
title={Parametric UMAP Embeddings for Representation and Semisupervised Learning},
author={Sainburg, Tim and McInnes, Leland and Gentner, Timothy Q},
journal={Neural Computation},
volume={33},
number={11},
pages={2881--2907},
year={2021},
publisher={MIT Press One Rogers Street, Cambridge, MA 02142-1209, USA journals-info~…}
}