使用 UMAP 进行文档嵌入
这是一个使用 UMAP 嵌入文本(也可扩展到任何标记集合)的教程。我们将使用 20 newsgroups 数据集,这是一个按主题标记的论坛帖子集合。我们将嵌入这些文档,并看到相似的文档(即 同一子论坛的帖子)将彼此靠近。您可以将此嵌入用于其他下游任务,例如可视化您的语料库,或运行聚类算法(例如 HDBSCAN)。我们将使用词袋模型,并在计数向量和 TF-IDF 向量上使用 UMAP。
首先,让我们加载相关库。这需要 UMAP 版本 >= 0.4.0。
import pandas as pd
import umap
import umap.plot
# Used to get the data
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
# Some plotting libraries
import matplotlib.pyplot as plt
%matplotlib notebook
from bokeh.plotting import show, save, output_notebook, output_file
from bokeh.resources import INLINE
output_notebook(resources=INLINE)
接下来,让我们下载并探索 20 newsgroups 数据集。
%%time
dataset = fetch_20newsgroups(subset='all',
shuffle=True, random_state=42)
CPU times: user 280 ms, sys: 52 ms, total: 332 ms
Wall time: 460 ms
让我们看看语料库的大小
print(f'{len(dataset.data)} documents')
print(f'{len(dataset.target_names)} categories')
18846 documents
20 categories
这是文档的类别。正如您所见,许多类别彼此相关(例如 ‘comp.sys.ibm.pc.hardware’ 和 ‘comp.sys.mac.hardware’),但它们并非全部相关(例如 ‘sci.med’ 和 ‘rec.sport.baseball’)。
dataset.target_names
['alt.atheism',
'comp.graphics',
'comp.os.ms-windows.misc',
'comp.sys.ibm.pc.hardware',
'comp.sys.mac.hardware',
'comp.windows.x',
'misc.forsale',
'rec.autos',
'rec.motorcycles',
'rec.sport.baseball',
'rec.sport.hockey',
'sci.crypt',
'sci.electronics',
'sci.med',
'sci.space',
'soc.religion.christian',
'talk.politics.guns',
'talk.politics.mideast',
'talk.politics.misc',
'talk.religion.misc']
让我们看几个示例文档
for idx, document in enumerate(dataset.data[:3]):
category = dataset.target_names[dataset.target[idx]]
print(f'Category: {category}')
print('---------------------------')
# Print the first 500 characters of the post
print(document[:500])
print('---------------------------')
Category: rec.sport.hockey --------------------------- From: Mamatha Devineni Ratnam <mr47+@andrew.cmu.edu> Subject: Pens fans reactions Organization: Post Office, Carnegie Mellon, Pittsburgh, PA Lines: 12 NNTP-Posting-Host: po4.andrew.cmu.edu I am sure some bashers of Pens fans are pretty confused about the lack of any kind of posts about the recent Pens massacre of the Devils. Actually, I am bit puzzled too and a bit relieved. However, I am going to put an end to non-PIttsburghers' relief with a bit of praise for the Pens. Man, they are killin --------------------------- Category: comp.sys.ibm.pc.hardware --------------------------- From: mblawson@midway.ecn.uoknor.edu (Matthew B Lawson) Subject: Which high-performance VLB video card? Summary: Seek recommendations for VLB video card Nntp-Posting-Host: midway.ecn.uoknor.edu Organization: Engineering Computer Network, University of Oklahoma, Norman, OK, USA Keywords: orchid, stealth, vlb Lines: 21 My brother is in the market for a high-performance video card that supports VESA local bus with 1-2MB RAM. Does anyone have suggestions/ideas on: - Diamond Stealth Pro Local --------------------------- Category: talk.politics.mideast --------------------------- From: hilmi-er@dsv.su.se (Hilmi Eren) Subject: Re: ARMENIA SAYS IT COULD SHOOT DOWN TURKISH PLANES (Henrik) Lines: 95 Nntp-Posting-Host: viktoria.dsv.su.se Reply-To: hilmi-er@dsv.su.se (Hilmi Eren) Organization: Dept. of Computer and Systems Sciences, Stockholm University |>The student of "regional killings" alias Davidian (not the Davidian religios sect) writes: |>Greater Armenia would stretch from Karabakh, to the Black Sea, to the |>Mediterranean, so if you use the term "Greater Armenia ---------------------------
现在我们将创建一个包含用于绘图的目标标签的数据帧。这将使我们能够在鼠标悬停在绘制点上时(如果使用交互式绘图)看到新闻组。这将帮助我们(通过肉眼)评估嵌入的效果如何。
category_labels = [dataset.target_names[x] for x in dataset.target]
hover_df = pd.DataFrame(category_labels, columns=['category'])
使用原始计数
接下来,我们将使用词袋方法(即 词序不重要),并构建一个词-文档矩阵。在此矩阵中,行对应于一个文档(即 帖子),每列对应于一个特定单词。值将是给定单词在特定文档中出现的次数的计数。
我们将使用 sklearn 的 CountVectorizer 函数为我们完成此操作,同时进行其他一些预处理步骤
通过空格分割文本为标记(即 单词)
删除英文停用词(the, and 等)
删除在整个语料库中出现少于 5 次的所有单词(通过 min_df 参数)
vectorizer = CountVectorizer(min_df=5, stop_words='english')
word_doc_matrix = vectorizer.fit_transform(dataset.data)
这给了我们一个 18846x34880 的矩阵,其中有 18846 个文档(与上面相同),34880 个唯一标记。该矩阵是稀疏的,因为大多数单词没有出现在大多数文档中。
word_doc_matrix
<18846x34880 sparse matrix of type '<class 'numpy.int64'>'
with 1939023 stored elements in Compressed Sparse Row format>
现在我们将使用 UMAP 进行降维,将矩阵从 34880 维降至 2 维(因为 n_components=2)。我们需要一个距离度量,并将使用海灵格距离,它衡量两个概率分布之间的相似性。每个文档都有一组由多项分布生成的计数,我们可以使用海灵格距离来衡量这些分布的相似性。
%%time
embedding = umap.UMAP(n_components=2, metric='hellinger').fit(word_doc_matrix)
CPU times: user 2min 24s, sys: 1.18 s, total: 2min 25s
Wall time: 2min 3s
现在我们得到了一个 18846x2 的嵌入。
embedding.embedding_.shape
(18846, 2)
让我们绘制嵌入结果。如果您在 Notebook 中运行此代码,则应使用交互式绘图方法,因为它允许您将鼠标悬停在点上并查看它们所属的类别。
# For interactive plotting use
# f = umap.plot.interactive(embedding, labels=dataset.target, hover_data=hover_df, point_size=1)
# show(f)
f = umap.plot.points(embedding, labels=hover_df['category'])
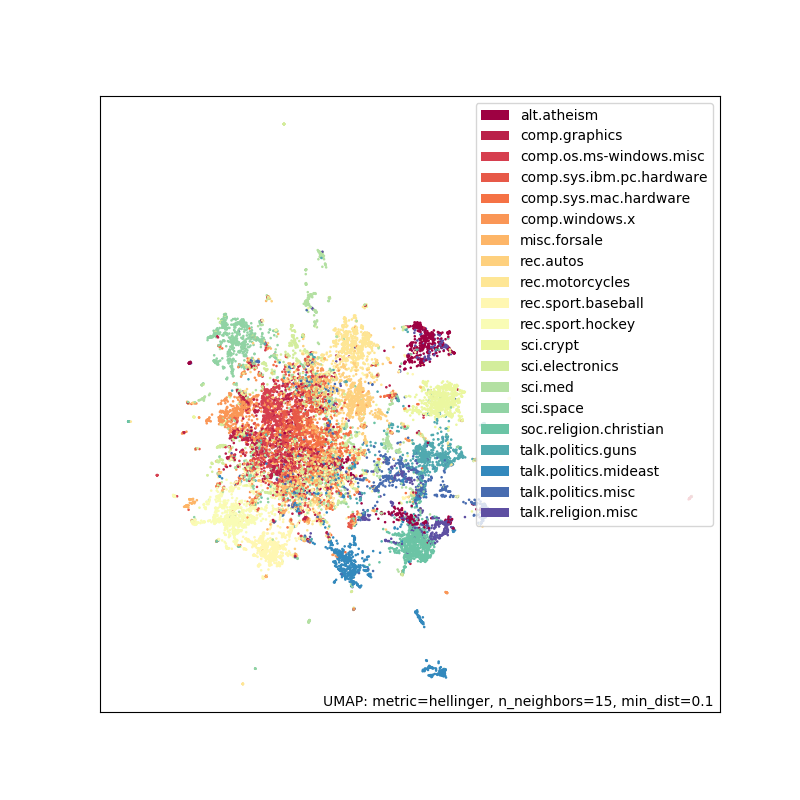
正如您所见,效果相当不错。有些分离,并且您期望相似的组(例如 ‘rec.sport.baseball’ 和 ‘rec.sport.hockey’)彼此靠近。中间的大簇对应于许多极其相似的新闻组,例如 ‘comp.sys.ibm.pc.hardware’ 和 ‘comp.sys.mac.hardware’。
使用 TF-IDF
现在我们将执行相同的流程,唯一的改变是使用 TF-IDF 加权。TF-IDF 对在大量文档中频繁出现的单词赋予较低的权重,因为它们通常更普遍。它对在较少文档子集中频繁出现的单词赋予较高的权重,因为这些单词可能对这些文档很重要。
为了进行 TF-IDF 加权,我们将使用 sklearn 的 TfidfVectorizer,参数与上面的 CountVectorizer 相同。
tfidf_vectorizer = TfidfVectorizer(min_df=5, stop_words='english')
tfidf_word_doc_matrix = tfidf_vectorizer.fit_transform(dataset.data)
我们得到了一个与之前大小相同的矩阵
tfidf_word_doc_matrix
<18846x34880 sparse matrix of type '<class 'numpy.float64'>'
with 1939023 stored elements in Compressed Sparse Row format>
再次,我们使用海灵格距离和 UMAP 来嵌入文档
%%time
tfidf_embedding = umap.UMAP(metric='hellinger').fit(tfidf_word_doc_matrix)
CPU times: user 2min 19s, sys: 1.27 s, total: 2min 20s
Wall time: 1min 57s
# For interactive plotting use
# fig = umap.plot.interactive(tfidf_embedding, labels=dataset.target, hover_data=hover_df, point_size=1)
# show(fig)
fig = umap.plot.points(tfidf_embedding, labels=hover_df['category'])
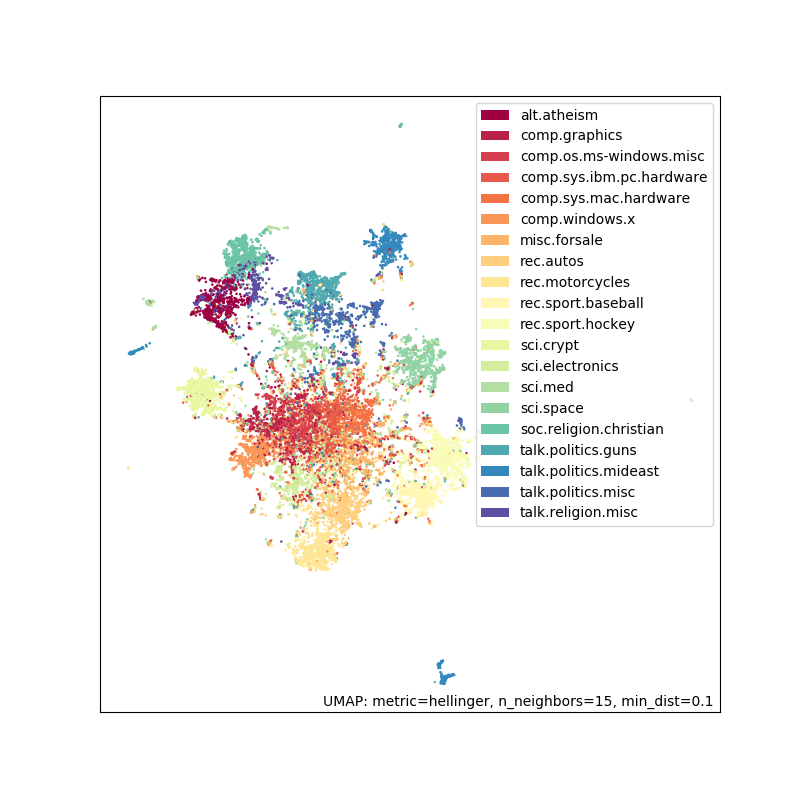
结果看起来与之前非常相似,但这可能是您的工具箱中一个有用的技巧。
潜在应用
现在我们有了嵌入,可以用它做什么?
探索/可视化您的语料库以识别主题/趋势
对嵌入进行聚类以找到相关文档组
寻找最近邻以找到相关文档
寻找异常文档