用于时变数据的 AlignedUMAP
数据集通常可以按段(通常是时间段)划分,我们不仅希望了解每段数据的结构,还希望了解该结构在不同段之间如何变化。美国国会成员随时间变化的相对政治倾向就是一个例子。在确定相对政治倾向时,我们可以查看代表在唱名投票中的投票记录,前提是政治原则相似的代表会有相似的投票记录。当然,我们可以查看任何一届国会的这类数据,但由于代表通常会连任,我们也可以考虑他们在国会中的相对位置如何随时间变化——这是 AlignedUMAP 的理想用例。
首先我们需要一些库。除了 UMAP,我们还需要进行一些数据整理;为此,我们需要 pandas,并且为了匹配代表姓名,我们将使用 fuzzywuzzy 库,它提供易于使用的模糊字符串匹配功能。
import umap
import umap.utils as utils
import umap.aligned_umap
import sklearn.decomposition
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from fuzzywuzzy import fuzz, process
import re
sns.set(style="darkgrid", color_codes=True)
接下来我们需要代表的投票记录以及唱名投票记录相关的元数据。您可以从 https://clerk.house.gov 获取数据;演示如何下载数据并将其解析为本文使用的 csv 文件的 notebook 可在此处获取 此处。
处理国会投票记录
投票记录为每位代表提供一行数据,其中 -1 表示“否”,0 表示“出席”或“未投票”,1 表示“是”。另一个 csv 文件包含所有投票的原始数据,每行记录每位立法者对每个唱名项目的投票。我们真正只需要一些元数据——他们代表哪个州和哪个政党,以便以后可以用这类信息修饰结果。为此,我们只需提取每年的姓名、州份和政党信息。我们可以获取这些列然后去除重复项。注意:政党信息有时会输入错误,代表偶尔也会更改政党,导致行重复。目前我们只取这些重复项中的第一个条目。
votes = [pd.read_csv(f"house_votes/{year}_voting_record.csv", index_col=0).sort_index()
for year in range(1990,2021)]
metadata = [pd.read_csv(
f"house_votes/{year}_full.csv",
index_col=0
)[["legislator", "state", "party"]].drop_duplicates(["legislator", "state"]).sort_values('legislator')
for year in range(1990,2021)]
让我们看看某一年的投票记录,了解我们正在查看的数据类型
votes[5]
| 104-1st-1 | 104-1st-10 | 104-1st-100 | 104-1st-101 | 104-1st-102 | 104-1st-103 | 104-1st-104 | 104-1st-105 | 104-1st-106 | 104-1st-107 | ... | 104-1st-90 | 104-1st-91 | 104-1st-92 | 104-1st-93 | 104-1st-94 | 104-1st-95 | 104-1st-96 | 104-1st-97 | 104-1st-98 | 104-1st-99 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| legislator | |||||||||||||||||||||
| Abercrombie | 0.0 | 1.0 | -1.0 | -1.0 | -1.0 | -1.0 | 1.0 | 1.0 | -1.0 | 1.0 | ... | -1.0 | -1.0 | 1.0 | -1.0 | 1.0 | -1.0 | -1.0 | 1.0 | 1.0 | 1.0 |
| Ackerman | 0.0 | 1.0 | -1.0 | 1.0 | -1.0 | -1.0 | 1.0 | 1.0 | -1.0 | 1.0 | ... | 1.0 | -1.0 | -1.0 | 1.0 | 1.0 | -1.0 | -1.0 | 1.0 | 1.0 | 1.0 |
| Allard | 0.0 | 1.0 | 1.0 | 1.0 | -1.0 | 1.0 | -1.0 | -1.0 | 1.0 | -1.0 | ... | -1.0 | -1.0 | -1.0 | -1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | -1.0 |
| Andrews | 0.0 | 1.0 | 0.0 | -1.0 | -1.0 | 1.0 | -1.0 | 0.0 | 0.0 | 0.0 | ... | -1.0 | 1.0 | -1.0 | -1.0 | 1.0 | 1.0 | -1.0 | 1.0 | -1.0 | -1.0 |
| Archer | 0.0 | 1.0 | 1.0 | -1.0 | -1.0 | 1.0 | -1.0 | -1.0 | 1.0 | -1.0 | ... | -1.0 | -1.0 | -1.0 | -1.0 | -1.0 | 1.0 | 1.0 | 1.0 | -1.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| Young (AK) | 0.0 | 1.0 | 1.0 | 1.0 | -1.0 | 1.0 | -1.0 | -1.0 | 1.0 | -1.0 | ... | -1.0 | -1.0 | -1.0 | -1.0 | -1.0 | 1.0 | 1.0 | 1.0 | -1.0 | -1.0 |
| Young (FL) | 0.0 | 1.0 | 1.0 | -1.0 | -1.0 | 1.0 | -1.0 | -1.0 | 1.0 | -1.0 | ... | -1.0 | -1.0 | -1.0 | -1.0 | -1.0 | 1.0 | 1.0 | 1.0 | -1.0 | -1.0 |
| Zeliff | 0.0 | 1.0 | 1.0 | -1.0 | -1.0 | 1.0 | -1.0 | -1.0 | 1.0 | -1.0 | ... | -1.0 | -1.0 | -1.0 | -1.0 | -1.0 | 1.0 | 1.0 | 1.0 | -1.0 | -1.0 |
| Zimmer | 0.0 | 1.0 | 1.0 | -1.0 | -1.0 | 1.0 | -1.0 | -1.0 | 1.0 | -1.0 | ... | -1.0 | 1.0 | -1.0 | -1.0 | -1.0 | 1.0 | 1.0 | 1.0 | -1.0 | -1.0 |
| de la Garza | 0.0 | 1.0 | 1.0 | 1.0 | -1.0 | 1.0 | 1.0 | 1.0 | -1.0 | 1.0 | ... | 0.0 | -1.0 | -1.0 | 1.0 | 1.0 | -1.0 | 1.0 | 1.0 | -1.0 | 1.0 |
438 行 × 885 列
我们可以查看同一年的相关元数据。
metadata[5]
| legislator | state | party | |
|---|---|---|---|
| 0 | Abercrombie | HI | D |
| 1 | Ackerman | NY | D |
| 2 | Allard | CO | R |
| 3 | Andrews | NJ | D |
| 4 | Archer | TX | R |
| ... | ... | ... | ... |
| 430 | Young (AK) | AK | R |
| 431 | Young (FL) | FL | R |
| 432 | Zeliff | NH | R |
| 433 | Zimmer | NJ | R |
| 89 | de la Garza | TX | D |
438 行 × 3 列
您可能会注意到,有时代表姓名后面会用括号列出州名。这是为了区分恰好拥有相同姓氏的代表。这实际上使事情复杂化了,因为只有在该届国会发生姓名冲突时才会应用消歧。这意味着代表可能在几年内只用他们的姓氏,然后切换到使用消歧名称,之后可能再切换回来。这将使得在代表的整个国会生涯中始终如一地跟踪他们变得困难得多。为了解决这个问题,我们将简单地通过一个包含代表姓名、政党和州份的唯一代表 ID 来重新索引所有投票数据帧。我们需要一个函数从元数据生成这些 ID,然后将其应用于所有记录。重要的是,我们需要通过一些 groupby 技巧来巧妙处理代表被列出两次(在无歧义和消歧义名称下)的情况。
def unique_legislator(row):
name, state, party = row.legislator, row.state, row.party
# Strip of disambiguating state designators
if re.search(r'(\w+) \([A-Z]{2}\)', name) is not None:
name = name[:-5]
return f"{name} ({party}, {state})"
for i, _ in enumerate(votes):
votes[i].index = pd.Index(metadata[i].apply(unique_legislator, axis=1), name="legislator_index")
votes[i] = votes[i].groupby(level=0).sum()
metadata[i].index = pd.Index(metadata[i].apply(unique_legislator, axis=1), name="legislator_index")
metadata[i] = metadata[i].groupby(level=0).first()
现在数据已经整理得初具规模,接下来是如何确保代表数据的连续性。为了让这更容易些,我们将使用跨越 四年期 的投票记录,而不是单年度记录。同样重要的是,我们将以滑动窗口的方式进行,这样我们先考虑 1990-1994 年的记录,然后是 1991-1995 年的记录,以此类推。通过这种方式重叠窗口,我们可以确保多年来政治立场的连续性稍微更强一些。为了实现这一点,我们只需按滑动对的方式合并数据帧,然后通过相同的方法合并这些对。
votes = [
pd.merge(
v1, v2, how="outer", on="legislator_index"
).fillna(0.0).sort_index()
for v1, v2 in zip(votes[:-1], votes[1:])
] + votes[-1:]
metadata = [
pd.concat([m1, m2]).groupby("legislator_index").first().sort_index()
for m1, m2 in zip(metadata[:-1], metadata[1:])
] + metadata[-1:]
那是年份对;现在我们将这些对成对合并,得到四年的投票记录集。
votes = [
pd.merge(
v1, v2, how="outer", on="legislator_index"
).fillna(0.0).sort_index()
for v1, v2 in zip(votes[:-1], votes[1:])
] + votes[-1:]
metadata = [
pd.concat([m1, m2]).groupby(level=0).first().sort_index()
for m1, m2 in zip(metadata[:-1], metadata[1:])
] + metadata[-1:]
应用 AlignedUMAP
为了使用 AlignedUMAP,我们需要在连续的数据集切片之间建立关系。在本例中,这意味着我们需要建立一个关系,描述一个四年期切片中的行如何对应于同一代表在下一个四年期切片中的行。为了让 AlignedUMAP 工作,这应该格式化为一个字典列表;每个字典提供从一个切片的索引到下一个切片的索引的映射。重要的是,这个映射可以是部分的——它只需要关联两个切片之间存在匹配关系的索引。
我们用于切片的投票数据帧已经使用代表的唯一标识符进行了索引,因此要建立关系,我们只需将它们匹配起来,创建一个从一个切片索引到另一个切片索引的字典。实际上,我们可以通过使用 pandas 在两个投票数据帧的 pandas 索引上合并数据帧来相对高效地完成此操作,其中数据只是行的数字索引。结果字典就是由内连接生成的对字典。
def make_relation(from_df, to_df):
left = pd.DataFrame(data=np.arange(len(from_df)), index=from_df.index)
right = pd.DataFrame(data=np.arange(len(to_df)), index=to_df.index)
merge = pd.merge(left, right, left_index=True, right_index=True)
return dict(merge.values)
创建关系的函数就绪后,我们只需将其应用于每对连续的投票数据帧。
relations = [make_relation(x,y) for x, y in zip(votes[:-1], votes[1:])]
如果您仍然不确定这些关系是什么,查看一些字典以及相应的投票数据帧对可能会有所帮助。这里是第一个关系字典的(部分)内容
relations[0]
{0: 0,
1: 1,
3: 2,
4: 3,
5: 4,
6: 5,
7: 6,
8: 7,
9: 8,
10: 9,
11: 10,
12: 11,
13: 12,
14: 13,
15: 14,
...
475: 547,
476: 549,
477: 550,
478: 552,
479: 553,
480: 554,
481: 555,
482: 556,
483: 557,
484: 559}
现在我们终于可以运行 AlignedUMAP 了。大多数标准 UMAP 参数都可用,包括选择度量和邻居数量。在这里,我们还将使用额外的 AlignedUMAP 参数 alignment_regularisation 和 alignment_window_size。第一个参数是一个衡量保持对齐重要性的权重值。通常这个值比这里设置的要小得多(默认值是 0.01),但考虑到投票记录中相对较高的波动性,我们将在这里增加它。第二个参数 alignment_window_size 决定了 AlignedUMAP 在对齐嵌入时会向两侧查看多远——即使关系仅在连续切片之间指定,它也会将它们链接起来构建更远距离的关系。在本例中,我们将使其向两侧查看最多 5 个切片。
%%time
aligned_mapper = umap.aligned_umap.AlignedUMAP(
metric="cosine",
n_neighbors=20,
alignment_regularisation=0.1,
alignment_window_size=5,
n_epochs=200,
random_state=42,
).fit(votes, relations=relations)
embeddings = aligned_mapper.embeddings_
CPU times: user 6min 7s, sys: 30.6 s, total: 6min 37s
Wall time: 5min 57s
结果可视化
现在我们需要以某种方式绘制数据。为了使可视化更有趣,最好有一些颜色变化——理想情况下能展示相对政治立场的不同视角。为此,我们希望尝试从另一个来源了解每位候选人的立场。为此,我们可以尝试提取代表获胜的选票差额。这里的问题是,尽管选举数据可以收集和处理,但由于来源不同,姓名并不能完美匹配。这意味着我们需要尽力为每位候选人找到匹配的姓名。我们将使用仅限于相关年份和州的模糊字符串匹配来尝试获得良好的匹配。一个提供获取和处理选举获胜者数据详细信息的 notebook 可在此处找到 此处。
election_winners = pd.read_csv('election_winners_1976-2018.csv', index_col=0)
election_winners.head()
| year | state | district | winner | party | winning_ratio | |
|---|---|---|---|---|---|---|
| 0 | 1976 | AK | 0 | Don Young | republican | 0.289986 |
| 0 | 1976 | AL | 1 | Jack Edwards | republican | 0.374808 |
| 0 | 1976 | AL | 2 | William L. \\"Bill\"\" Dickinson" | republican | 0.423953 |
| 0 | 1976 | AL | 3 | Bill Nichols | democrat | 1.000000 |
| 0 | 1976 | AL | 4 | Tom Bevill | democrat | 0.803825 |
现在我们只需遍历元数据,用从选举获胜者数据中收集到的额外信息填充它。由于我们无法进行精确的姓名匹配(关于姓名等文本字段,两边的数据都有点混乱),我们不能简单地执行连接操作,而必须按年和按代表逐个处理,为给定年份和州的选举找到我们能做到的最佳姓名字符串匹配。实际上,我们无疑会弄错其中一些,如果目标是基于这些数据进行严谨的分析,则需要更加小心。由于这只是一个演示,并且我们只将这些额外信息用作绘图中的颜色通道,我们可以原谅一些不精确数据处理导致的错误。
n_name_misses = 0
for year, df in enumerate(metadata, 1990):
df["partisan_lean"] = 0.5
df["district"] = np.full(len(df), -1, dtype=np.int8)
for idx, (loc, row) in enumerate(df.iterrows()):
name, state, party = row.legislator, row.state, row.party
# Strip of disambiguating state designators
if re.search(r'(\w+) \([A-Z]{2}\)', name) is not None:
name = name[:-5]
# Get a party designator matching the election_winners data
party = "republican" if party == "R" else "democrat"
# Restrict to the right state and time-frame
state_election_winners = election_winners[(election_winners.state == state)
& (election_winners.year <= year + 4)
& (election_winners.year >= year - 4)]
# Try to match a name; and fail "gracefully"
try:
matched_name = process.extractOne(
name,
state_election_winners.winner.tolist(),
scorer=fuzz.partial_token_sort_ratio,
score_cutoff=50,
)
except:
matched_name = None
# If we got a unique match, get the election data
if matched_name is not None:
winner = state_election_winners[state_election_winners.winner == matched_name[0]]
else:
winner = []
# We either have none, one, or *several* match elections. Take a best guess.
if len(winner) < 1:
df.loc[loc, ["partisan_lean"]] = 0.25 if party == "republican" else 0.75
n_name_misses += 1
elif len(winner) > 1:
df.iloc[idx, 4] = int(winner.district.values[-1])
df.iloc[idx, 3] = float(winner.winning_ratio.values[-1])
else:
df.iloc[idx, 4] = int(winner.district.values)
df.iloc[idx, 3] = float(winner.winning_ratio.values[0])
print(f"Failed to match a name {n_name_misses} times")
Failed to match a name 100 times
现在我们根据选区选举差额得到了相对党派倾向,我们可以给图着色了。我们显然可以用代表姓名标记图。最后一个需要注意的问题(使用 matplotlib 绘图时)是获取绘图边界(因为我们将直接将文本标记放置在图中,因此不会自动生成边界)。这只需计算一些略超出数据范围的调整后的边界即可。
def axis_bounds(embedding):
left = embedding.T[0].min()
right = embedding.T[0].max()
bottom = embedding.T[1].min()
top = embedding.T[1].max()
width = right - left
height = top - bottom
adj_h = width * 0.1
adj_v = height * 0.05
return [left - adj_h, right + adj_h, bottom - adj_v, top + adj_v]
现在开始绘图。让我们随机选择一个时间切片(欢迎尝试其他切片),并在该切片的嵌入位置绘制代表姓名,根据他们的相对选举获胜差额进行着色。
fig, ax = plt.subplots(figsize=(12,12))
e = 5
ax.axis(axis_bounds(embeddings[e]))
ax.set_aspect('equal')
for i in range(embeddings[e].shape[0]):
ax.text(embeddings[e][i, 0],
embeddings[e][i, 1],
metadata[e].index.values[i],
color=plt.cm.RdBu(np.float32(metadata[e]["partisan_lean"].values[i])),
fontsize=8,
horizontalalignment='center',
verticalalignment='center',
)
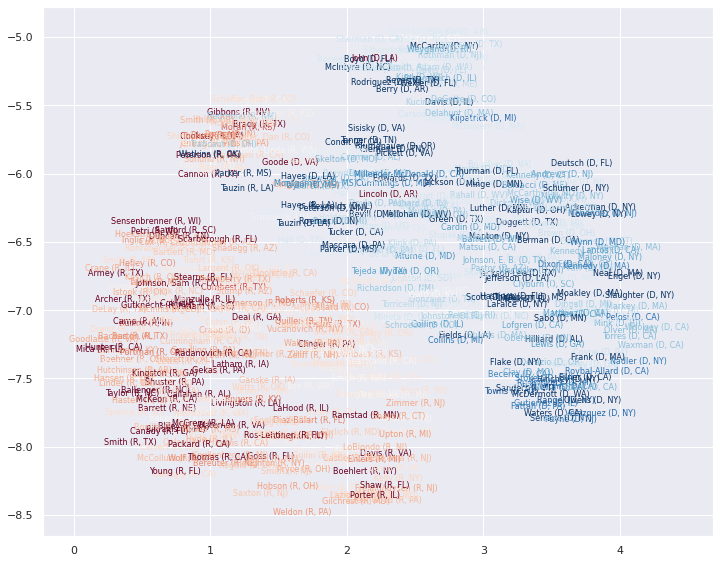
这很好地展示了单个时间切片中的布局,通过绘制不同的时间切片,我们可以了解事物如何演变。然而,我们可以更进一步,将代表绘制成随时间变化的曲线,展示他们在国会中相对政治立场的演变。为此,我们需要一个 3D 图——我们需要 UMAP 的 x 和 y 坐标,以及表示年份的第三个坐标。我发现使用 plotly 最容易做到这一点,所以我们导入它。为了绘制随时间变化的平滑曲线,我们还将导入 scipy.interpolate 模块,它允许我们从代表随时间出现的离散位置插值出平滑曲线。
import plotly.graph_objects as go
import scipy.interpolate
为此将数据整理成所需的形状是下一步;首先,我们将所有数据放入一个数据帧中,以便根据需要从中提取相关数据。
df = pd.DataFrame(np.vstack(embeddings), columns=('x', 'y'))
df['z'] = np.concatenate([[year] * len(embeddings[i]) for i, year in enumerate(range(1990, 2021))])
df['representative_id'] = np.concatenate([v.index for v in votes])
df['partisan_lean'] = np.concatenate([m["partisan_lean"].values for m in metadata])
接下来,我们需要对给定代表的曲线进行插值。我们将编写一个函数来处理这个问题,因为它涉及一些使其不简单的基于案例的逻辑。我们将获得年份数据,并希望对单个代表的 UMAP x 和 y 坐标进行插值。
第一个主要问题是许多代表在国会中不是连续任职的:他们可能当选几年,然后未能连任,几年后又回到国会(可能在另一个选区)。每一个这样的连续年份块都需要成为一条单独的路径,我们不应该将它们连接起来。因此,我们需要一些逻辑来找到这些连续块并为每个块生成平滑路径。
另一个问题是有些代表只任职了一两年(特殊选举等),我们无法对此进行三次样条插值;对于这些情况,我们可以降级使用线性插值或二次样条,对于一些单年度情况,只需添加点本身即可。
解决了这些问题后,我们就可以简单地使用 scipy 的 interp1d 函数通过这些点生成平滑曲线。
INTERP_KIND = {2:"linear", 3:"quadratic", 4:"cubic"}
def interpolate_paths(z, x, y, c, rep_id):
consecutive_year_blocks = np.where(np.diff(z) != 1)[0] + 1
z_blocks = np.split(z, consecutive_year_blocks)
x_blocks = np.split(x, consecutive_year_blocks)
y_blocks = np.split(y, consecutive_year_blocks)
c_blocks = np.split(c, consecutive_year_blocks)
paths = []
for block_idx, zs in enumerate(z_blocks):
text = f"{rep_id} -- partisan_lean: {np.mean(c_blocks[block_idx]):.2f}"
if len(zs) > 1:
kind = INTERP_KIND.get(len(zs), "cubic")
else:
paths.append(
(zs, x_blocks[block_idx], y_blocks[block_idx], c_blocks[block_idx], text)
)
continue
z = np.linspace(np.min(zs), np.max(zs), 100)
x = scipy.interpolate.interp1d(zs, x_blocks[block_idx], kind=kind)(z)
y = scipy.interpolate.interp1d(zs, y_blocks[block_idx], kind=kind)(z)
c = scipy.interpolate.interp1d(zs, c_blocks[block_idx], kind="linear")(z)
paths.append((z, x, y, c, text))
return paths
现在我们可以使用 plotly 绘制结果曲线了。对于 plotly,我们使用 Scatter3D 方法,该方法支持“lines”模式,可以在 3D 空间中绘制曲线。我们可以根据从选举数据得出的党派倾向得分给曲线着色——实际上,颜色可以随着选举差额的变化在轨迹上变化。由于这是 plotly 图,它是交互式的,所以您可以旋转它并从各个角度查看。
不幸的是,交互式 plotly 图无法很好地嵌入到文档中,因此我们在此处展示一张静态图片。但是,如果您自己运行此代码,您将获得交互式版本。
traces = []
for rep in df.representative_id.unique():
z = df.z[df.representative_id == rep].values
x = df.x[df.representative_id == rep].values
y = df.y[df.representative_id == rep].values
c = df.partisan_lean[df.representative_id == rep]
for z, x, y, c, text in interpolate_paths(z, x, y, c, rep):
trace = go.Scatter3d(
x=x, y=z, z=y,
mode="lines",
hovertext=text,
hoverinfo="text",
line=dict(
color=c,
cmin=0.0,
cmid=0.5,
cmax=1.0,
cauto=False,
colorscale="RdBu",
colorbar=dict(),
width=2.5,
),
opacity=1.0,
)
traces.append(trace)
fig = go.Figure(data=traces)
fig.update_layout(
width=800,
height=600,
scene=dict(
aspectratio = dict( x=0.5, y=1.25, z=0.5 ),
yaxis_title="Year",
xaxis_title="UMAP-X",
zaxis_title="UMAP-Y",
),
scene_camera=dict(eye=dict( x=0.5, y=0.8, z=0.75 )),
autosize=False,
showlegend=False,
)
fig_widget = go.FigureWidget(fig)
fig_widget
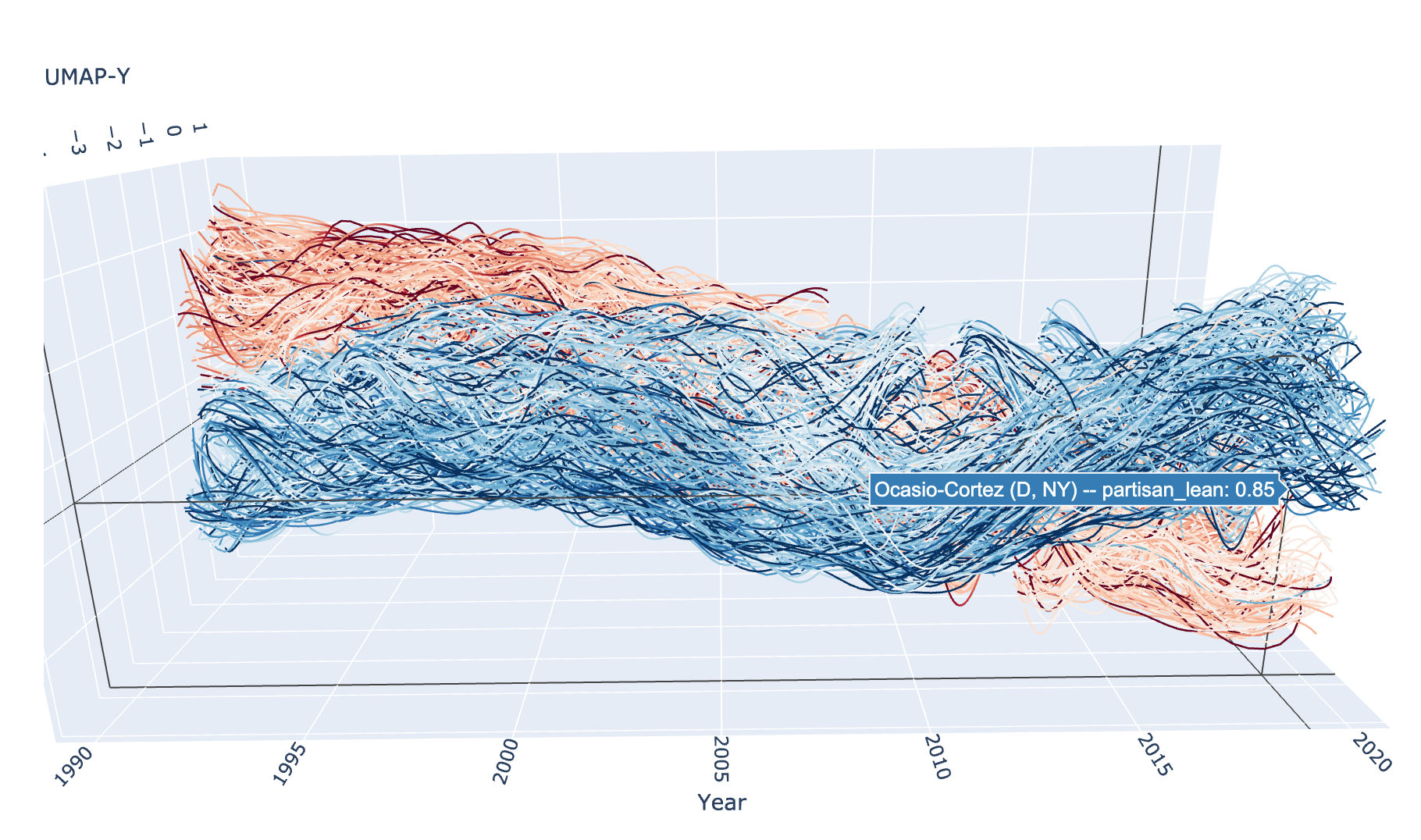
我们的探索到此结束。